This is the second series describing the ADD: a radically more productive development and delivery environment. The first article is here: Intro and described the truth and lies about developing software. The second article dealt with ‘Testing’. The third dealt with the application stack (Grails and other technologies). The fourth discussed UI alternatives. The fifth added some major aspects to the stack: Semi-Structured Data, Templates, and Dual or Isomorphic scripting. The sixth discussed UI frameworks in a bit more detail and ended with an Angular vs. Ember as a core choice. The seventh went into logging, analytics, and monitoring of the running applications and nodes. The eighth was an overview of Federation Components like caches, queues, payment services, and the like. The ninth was on a highly reliable, scalable, flexibly, and ultimately very simple worker model.
WAR!
Continuing with the worker model, we currently have a non-production Application Server running Grails:
It is running grails ‘interactively’ and ‘off-source’. This is fast for deployment, but it is missing a few things that people usually want in production:
- Well-defined artifact that has been tested and can’t “just change”
- A container environment that can provide certain resources to the application (e.g. monitoring)
- Removal of having to understand the ‘building’ technology from the running technology (JVM)
- That production has as few technologies as possible, and is normally missing ‘compilers’ so people can’t tweak behavior
The last item is (IMO) a bit paranoid, and there are better ways to make sure production is stable (tripwires and
logging). And the third is probably unrealistic for anything but trivial debugging.
But the first two are certainly reasonable wants. A lot of people are familiar with deploying wars and deploying
wars on Tomcat and other servers.
Where’s the WAR?
The first issue with changing from source deployment to war-based deployment is “Where is the WAR?” and “How do I know it has changed?”. As with the other weird primary ingredient approaches, the WAR is going to be in an annexed repository. And you can see that it changed by simply looking at whether the ‘git revision’ of the war has changed. This approach gives incredible power and flexibility:
- You can have as many different versions of the application as you want. They just each have to have their own ‘folder’
- You can easily see which deployments are using which versions
- Changing a deployment to use a different version involves copying a 50 byte hash vs. an actual WAR file
- Getting the real file is a super-fast call to S3
- Bootstrapping the initial version is the same as any other version, which makes it less likely to diverge and break
The WARs should be in a different repository from the source for a number of reasons, but the main one being their rules and rythms are very different. But the structure of the repositories can be very similar to make it easy to see the created artifacts. Something like this:
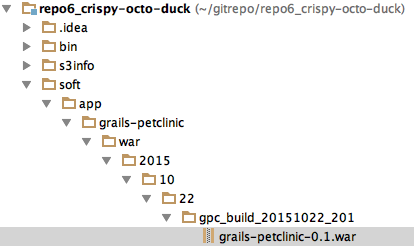
Note that the contents of the directory could be anything. And actually a ‘trick’ to making the upload much faster is to use an exploded ‘war’ vs. a normal ‘war’. Why? Because a WAR contains a bunch of jars that are all almost always identical between versions. So although S3 has basically unlimited space, it is silly to waste it with a file that (although different) is 99% the same between each version. For example, all the identical jars within this expanded war:
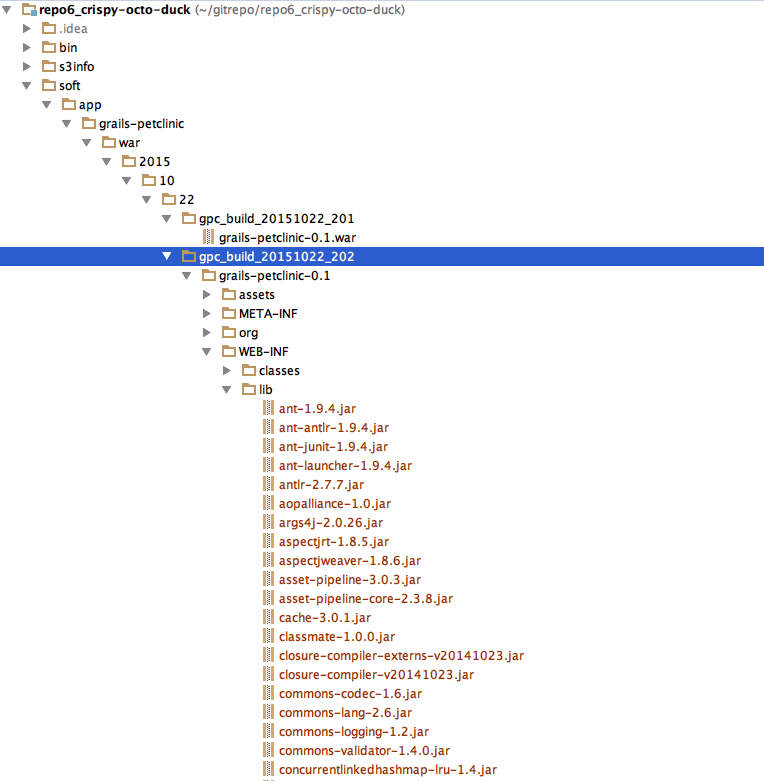
The trade is that you have a lot more files in the other folders. Finally, you could do a hybrid where everything but the lib folder is compressed. To make the real war, your deployment process would uncompress and then re-WAR the contents.
The performance difference is dramatically different when working outside the EC2 grid, but is less so within that grid.
Who deploys what? The Promotion model
The deploying server needs to watch something so it can see a change that is relevant to it. Production does not care that there is a new QA build. And QA may not care there is a new development build. QA never creates its own build, but it only cares when a development build is “Good enough to QA”. This I call the promotion model.
For any given application:
- Automated builds occur all the time (whenever something changes) and each gets a unique identifier (e.g. 201)
- Each build is then promoted through however many levels of inspection you want
- If it passes muster
- If it has not been superseded by another build
- If not, it is ignored
With this model, you never go backward, which increases productivity a lot. And your are continuously trying to go forward, which means you have very current information about where you are. And this also increases productivity. Yes, in a pinch, you could see if a build between last success and most current can be promoted. But that is impacting productivity so it should rarely be done.
This also implies there is no branching. One source. One set of builds based on that source. That is not required by this approach (branch source, new set of builds), but it is strongly encouraged because it again wastes no energy and it is trivial to flip to a different ‘set of builds’ when a branch/back-patch is required. But the process is very optimistic while also being very realistic (the world is where it is) and appropriately pessimistic (you can’t promote through QA until you pass the automated tests). Because machines embody the process, you can’t subvert it without doing it very conspicuously
To be promoted, you just have to be ‘copied’ into the right destination. Promotions are more an ‘it’ than a ‘development’ activity, so they are structured under the ‘it’ folder. Each federation (and potentially part) has it’s own versions of things. If you are in ‘fed1’ and want the ‘grails-petclinic’ application on your machine, you know where to look: ‘fed/fed1’. The use of ‘common’ vs. ‘stacktype’ is mirroring the flexibility shown elsewhere. You could have most deployments use ‘common’ and have some override it. Or most deployments override ‘common’ but there is a default in case they don’t.
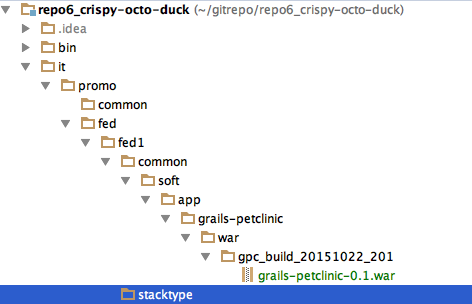
Who builds and deploys? Custom Worker vs. Chores
OK, so we need to build and deploy every time a particular repository changes. We could do that monolithicly and have no registry of the war being built (it just magically happens), or we could do that in two parts:
- Detect change in repository: create chore to build war
- Detect chore and worker do chore
The advantage of the second version is we can decompose figuring out what needs to be done from doing it, and we also have better visibility and consistency in the process. Although I like doing things incrementally, I don’t think the increment (monolith) is notably simpler than the second, and this was meant to build on our Worker topic.
The critical question is actually ‘who is going to write the chore’. We don’t want to have a bunch of chores created by different workers who all recognized a change was done. Fortunately, we already have a model for this with the ‘chore’ ownership. We need to describe an ‘event’ in a way that is related to whatever has changed about the world, and then when trying to ‘create the chore’ a worker first ‘creates the event’. Once an event is created and ‘pushed’, there is no reason to create it again.
In this case, the event is pretty obvious to describe: a git repository went to a new version or specifically:
- repo3_miniature-ironman
- 551b86e42d…
so if an event for that exists, don’t create another one. Since this is a simple identification, we don’t need the extra directory structure and can simply write a ‘.json’ file into the appropriate time directory. Note the time should be the time of the ‘event’, not of when it was noticed.
A given event could trigger multiple chores, but in our case we just want to have the one ‘build the war’ chore created. Note that the chore could be trivial: it could result in no work being done except seeing if a new WAR is needed. Chores are rarely ‘you must do this’, but more ‘do this if necessary’. This alows us to be fast in the creation of the ‘chore’ vs. doing a lot of analysis up front. Since the worker pool can be large, we don’t want any given worker to block the pipeline too much.
Event structure
The structure of the event can be anything. It is nice to have the JSON be declarative of what it is (an ‘event’) and then have enough information to process the information. Some human readable information is handy for debugging and logging.
1 2 3 4 5 6 7 8 9 10 11 12 | |
Chore structure
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Making it happen
Although I mentioned before that there were ‘parents’, ‘workers’, and that application servers shouldn’t do any of this kind of work, with this very clean pipeline it is clear our single application server could easily do all of this itself. So just to save on IT, that will be the first version. After that it is easy to see we could separate the ‘parent/worker’ from the application server. And although likely not necessary, we could separate the ‘parent’ from the ‘worker’ node too. The reason the ‘parent’ doesn’t need to be separated is we should always have two parents around and a simple CloudFormation can make sure that is true. And parents don’t do that much, so there is no reason to have them be separate from workers. With this model, all workers are also potential parents, and there are always two workers available.
Detecting the change to ‘Repo3’
This is actually the same script as before where we just do something different in the ‘ActualWork’ source:
1 2 3 4 5 6 7 | |
So now we know we have to do the work, but we need to see if it was already done by someone else:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
If this push succeeds, we are free and clear. If not, we can try to merge (maybe some other event or chore was written) and push again with a quick ‘git pull; git push’. We could do that “forever” or until we know we have no hope (study the actual output of the git pull, push, or other metadata between the two branches). For the first pass, we can just do it once.
Event poster also chore poster
Since we know we detected the ‘event’ first, we are the owner of the event and can now safely write out the ‘chores’ associated with the event.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Detecting and doing the chore
We went through detecting the chore before AddStack-9, but now we want to do something with the chore.
Given the chore is describe in JSON and what we do for the chore could be complex, we should switch to a higher level language than ‘bash’. In this case we can go into Python as a decent scripting language:
1
| |
This implies a powerful chore processing script, or one that can modularly call other scripts. As long as the script leads the creation of ‘chore’ types, we should be fine whether monolithic or modular.
The core of the routine is just to extract the necessary information from the JSON
1 2 3 4 5 6 7 8 9 10 11 12 | |
With this information we can then go to the build repository, do a simple ‘grails package’, and copy it to the appropriate repo and path.
Other ‘chores’ for this event?
The event that caused the ‘buildwar’ chore could also cause other activities. Each of the application servers could create their own ‘chore’ to redeploy, which would enable the ‘event’ and ‘chore’ repository to reflect system activity on a broader sense. Because they are doing the chore themselves, it would just be a way to log the activity vs. being a way to pass it out to a bunch of workers.
Conclusion
The event, chore, and worker model is a very flexible, reliable, and scalable way to get stuff done. It is
especially good at keeping throughput under control even when tasks can get onerous or ‘herding’ occurs.
As the backlog grows, more workers appear to keep it in control. When the backlog shrinks the workers go
to sleep or decommission.
The biggest issue with the worker approach is to make sure you know the ramp rate and reliability. Even with a huge cloud like EC2, there can be stutters and you have to more aggressively try to get resources, or accept that the user experience may be a bit more lagged.