This is the second series describing the ADD: a radically more productive development and delivery environment. The first article is here: Intro and described the truth and lies about developing software. The second article dealt with ‘Testing’. The third dealt with the application stack (Grails and other technologies). The fourth discussed UI alternatives. The fifth added some major aspects to the stack: Semi-Structured Data, Templates, and Dual or Isomorphic scripting. The sixth discussed UI frameworks in a bit more detail and ended with an Angular vs. Ember as a core choice. The seventh went into logging, analytics, and monitoring of the running applications and nodes. The eighth was an overview of Federation Components like caches, queues, payment services, and the like.
Workers!
Among the more interesting federation / deployment component are workers. Workers are interesting because they can do almost anything imaginable and they do it very efficiently. How efficiently? Well, the perfect worker is at 100% when doing a task and dead when they have no tasks to do. That is pretty darn efficient because it approaches 100% and is only not 100% when we choose to not accept the ‘spin up’ latency of getting a new worker. As the amount of work increases, our pool of workers increase, and the spin-up-latency decreases on a per-chore basis. That is very cool: as scale goes up, efficiency increases. There are a lot of places that is not true for computers, so it is nice when it is.
Work? Chore?
So we want to have a worker model where we can add a ‘chore’ (a unit of work, using a term not otherwise used in IT and CS… job, task, etc. are now ambivalent) to a queue of work-to-be-done, and have something do that chore. There are a lot of ways to do this:
- Use BeanStalk
- Use Kafka with a bunch of consumers
- Use a database and launch a worker if none is available
- Use Quartz and coordinate amongst the application servers which one is going to do the work
- Use GitHub and launch one or more workers as needed
And that is just a minor collection of simple solutions. The first two are probably ‘the best’ in terms of having a very clean model. But they require additional infrastructure and I am trying to keep that at a minimum. The second is using a database as a WorkQueue. Well, it turns out that this is actually commonly done and almost always regretted. Most databases are horrible with the characteristics of Chores and their lifecycle. So it does work, but not well.
The fourth is quite functional but not scalable. You don’t want your application servers doing a lot of work. A little housekeeping is fine. But the whole point of the Worker model is to enable as many or as few workers who each always do a lot of work. And then go away if no longer needed. That isn’t the lifecycle and duty of application servers.
So if you haven’t guessed by now, I am going to describe the fifth approach. Use an annexed Git repository to describe chores, their media (if any), and to provide the results (if any). It turns out to be blazingly fast, scalable, and flexible. A little weird but sometimes weird really works.
Chores, Parents, and Workers
A lot of time, the real world can seriously inspire the computer world. The Worker model I am about to describe matches a ‘high-speed’, ‘high-efficiency’, parenting model. I would guess any parent can see the similarities and even the Nirvana of this Worker model. It has a few major components:
- The World creates some Chores in a to-do list
- The World doesn’t want to do the Chores, because it has other things to do
- So The World creates two or more adults (for redundancy) so they can do the Chores
- And then The World gives responsibility to the adults to do the Chores
- The adults don’t want to actually do the Chores themselves, so they produce Workers to do the Chores
- The Workers are so awesome that they automatically all try to do the Chores, as quickly as possible
- The adults (Parents) have worked out a system to prevent two Workers from doing the same Chore
- If the Chores are not getting done fast enough, the Parents produce more Workers
- If there is no more work to do, the Workers go to sleep
- Waking periodically to see if there is more work
- Or if the Chores are not getting done fast enough, the Parents wake one or more Workers
With this model:
- The World is the Application Server or something similar
- The Parents are special Nodes (or processes on Application Server nodes) that can see the ‘to-do’ list
- The Workers are special Nodes that are created as the ‘to-do’ list backlog gets larger
You need at least two Parents at all time to make sure the To-Do list is being watched. You don’t need any Workers until the To-Do list is sufficiently long or latent.
We will put the ‘To-Do’ chores into a specially structured, annexed, Git repository. Because of the annexing, resources are automatically ‘deduped’ and having each ‘chore’ be self-contained is both possible and space efficient. Imagine all the ‘jar’s needed for a java build. Given most of these are stable between builds, they cost nothing at all to include in a ‘chore’. Where people run fragile artifact servers (fragile because (a) they exist as something that could fail and (b) they are rarely run redundantly) that have to handle heavy load, the Annex puts all that load on S3… which is designed from the ground-up for loads well beyond our workers.
Chore Structure
The core of a Chore has to include:
- The identity of the chore
- And an ability to ‘take it on’
- What the instructions are for the chore
- What resources you need for the chore
- Where the results of the chore are supposed to go
To make the throughput easier to see, we will organize chores by time. So basically a queue. We can have ‘priority’ within the metadata of the chore if we want things to jump the queue. And we can have different chore types (or IT needs) to make sure a worker can really handle the chore. Using the ‘cron_1m’ model of things working on the minute, we will put things into buckets every minute. But workers have to look for any not-done chore and pick it up if they can.
An advantage of the one-minute cron is we automatically can have a nice 30-second jitter. That plus some kind of randomization in chore selection makes it very unlikely that workers will acquire the same chore at the same time. But if they do, one will win due to ‘git push’ timing.
Identity
Chores are identified by their ‘producer’ and a timestamp. A ‘producer’ is a node plus a process id, and the timestamp can have any precision necessary for the process to know it can’t collide with itself. Two of the banes of any identity system is making sure identity is unique and not having a bottleneck for identity generation. The identity proposed solves these two main issues. A third requirement (sometimes) is keeping identity short / consistent. A hash of the ‘phrase’ is possible if necessary, but collisions could be an issue if the phrase is too short.
Instructions
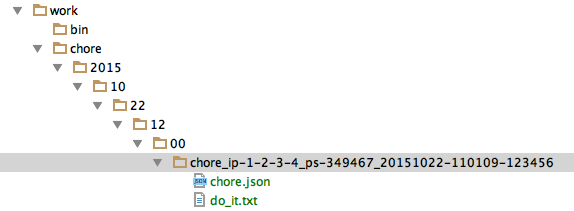
So we have something like “chore_ip-1-2-3-4_ps-349467_20151022-110109-123456” as a chore. This is simply a directory with a ‘chore.json’ within it where that ‘chore.json’ looks something like this:
1 2 3 4 5 6 7 8 9 | |
Another file is in the directory initially called ‘do_it.txt’ which can be empty.
Take on the ‘chore’
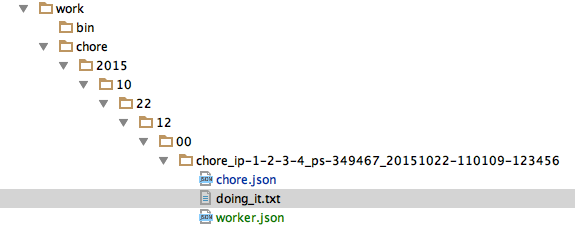
To take this ‘chore’ on, a worker adds a ‘worker.json’ file to the directory:
1 2 3 4 5 6 7 8 | |
and renames the ‘do_it.txt’ to ‘doing_it.txt’
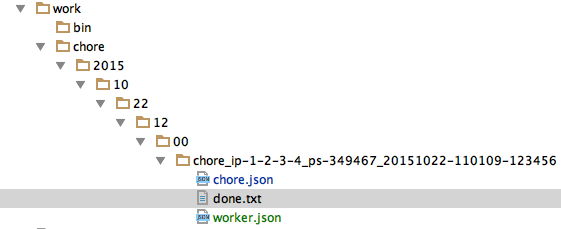
When these changes commit and push successfully, this worker now owns the chore. The worker can update the ‘worker.json’ through the work if desired, or put files into the directory or elsewhere. When the chore is complete, the worker should change worker.json to a finished state, and rename the ‘doing_it.txt’ to ‘done.txt’. With this, the three states are:
- do_it.txt
- doing_it.txt
- done.txt
And everyone can quickly tell what the state of a chore is without worrying about the details. Or dive into the json and results to figure out those details.
Visually it would look likte this:
The script to acquire a chore is a little involved because of the possibility of failure, but basically it just
- Finds all the ‘doit.txt’ files
- Picks one at random
- Tries to rename it and push that change
- If successful, then we are in. If not, roll-back
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Doing the work
A worker should alway be able to acquire:
- The root of the work repository – Say “${GIT_ROOT}”
- The root of the chore itself – Say “${CHORE_ROOT}”
Where the “GIT_ROOT” can have shared scripts in its ‘work/bin’ or ‘bin’ directories, and the chore can have individual scripts in it CHORE_ROOT/bin directory. We also likely have ‘repo2’ available, so we have access to a lot of resources (common and work specific) to leverage.
Saving the work
When the worker is done, it needs to do a final ‘write’ of all the results. This could be nothing more than logs (a worker is ‘anonymous’ and ephemeral, so ideally logs go to the chore’s directory vs. somewhere effectively ‘random’). This is just a final pull-push:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
and as long as this is successful, the work is done.
Jitter
Although the randomization of chore selection helps with a lot of chores, it does not help when there are very few chores left. On the ‘go’ of chore selection, all the workers go after the chore. So we need to say ‘go’ at different times. This brings back the ‘jitter’ concept mentioned previously. To jitter in this case, we just create a ‘random’ number and then modulo it by whatever jitter interval we want.
For example, using the process id plus the time stamp, and trying for a 0-29 range, we can have:
1 2 3 | |
Conclusion
The above is a very generic worker model that enables all kinds of flexibility in setting up ‘chores’ and scalably having a ‘right-size’ for the number of workers doing the work. The next article will be more specific and build new ‘wars’ every time the application changes after passing the built-in tests.