This is the fourth in a series of using git as part of interesting solutions to problems.
The first is here: Intro
Leveraging git to help enable automated IT
Doing IT for computers involves installing software, configuring things, doing backups, updates, etc. The ultimate IT is one that ‘simply works’ and involves almost no human interaction even in failure situations. Ideally IT should be equivalent to a macro-level program that does everything that does not require touching a physical machine.
This IT-as-program has become easier and easier over the last many years with better and more standardized operating systems, free software that does not require annoying human interaction during installation, and virtualization on top of physical hardware that makes provisioning and reprovisioning easier. With cloud computing, IT-as-program becomes almost a necessity as hundreds of virtual computers are created, updated, failed, migrated, and decommissioned.
Git alone doesn’t enable IT-as-program but it can be a core component in many areas. Among these are:
- Easy ‘Live IT’ servers
- A Push-Me-Pull-You model for continual deployment
- Server presence
Having git as a core piece of IT infrastructure enables thousands of machines to very rapidly react (within a minute or two) without needing a heavy infrastructure. You simply need one or two (for redundancy) git servers, of which one can be GitHub or a similar free or inexpensive service. Other technologies in this space have significantly more complicated servers, are more likely to be SPOFs (Single points of failures) or bottlenecks, and are much more expensive as a service.
Easy ‘Live IT’ servers
A ‘Live IT’ server is one that can automatically do new things when something about the IT world changes. This is not referring to how sophisticated the applications on a server are, but whether the server itself can manage upgrades or other configuration changes to itself. Examples are:
- Deploying new version of a Java war or a Rails app
- Doing database backups and offloads
- Offloading or deleting logs (that are harder than logrotate)
- Reacting to simple configuration changes
- Reacting to server presence changes
There are a number of ways to do the activities listed above, from manually interacting with machines, through cron jobs, mass ‘push’ model interactions (e.g. Capistrano), and finally puppetry via Chef and similar. I have found almost all of these to be lacking in many ways, including:
- Lack of documented change-to-server
- Difficulty in rolling back changes
- Not scaling nicely (one client hitting many servers, or many servers doing queries against another server)
- Lack of flexibility
- Slowness or non-responsiveness (delays) of applying changes
- Differences from ‘bootstrap’ of cloud servers
Pull Model
A different approach leveraging Git (or any other DVCS) seems to produce much simpler and more powerful solutions. The approach is composed of:
- A git repository that has working scripts (in any language people like, including Chef-solo)
- A simple bootstrap script that clones the repository and calls an
init.shscript in it - A cron job that is set up by the
init.shscript. This cron job executes every minute- Goes into the working git repository
- Does a pull to get the latest version of scripts
- Then calls into a
work.shscript
This flow enables activity at every minute, using the latest version of the git repository, and with very little overhead for the core behavior. Advantages are:
- All changes to a server are caused by one or more git repositories changing. Servers can even publish there status by showing the git revision they are on.
- Rolling back changes is simply reversing a commit
- The only centralized activity is the
git fetchwhich is very simple and fast. - So far the only constraint is the time is every minute, and that could be sub-minute but needing that is rare
- Delays are at most a minute, and again that could easily become less (but not sub-second)
- The behavior is actually the same as bootstrapping a server. A bootstrap is just the first minute of work.
Example-1
Example-1 is the initial example of this model. The repository is
with the CloudFormation template being:
This has a UserData section which does the initial bootstrap of cloning the repository and calling an init script inside it.
1 2 3 4 5 6 7 | |
The init.sh script simply sets up a cron job that calls the cron_1m.sh script
in /root/bin/. I prefer to have crontab files that are very simple (e.g. one line)
and call into /root/bin/ scripts so (a) it is more visible what crons are running
(b) if there are any inter-cron issues they can be managed, and (c) it is easy to
disable a cron by doing a rename.
The init.sh file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
And the cron_1m.sh file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
As you can see the cron_1m.sh script is “repo flexible”.
It will do any and all work.sh file it finds in the repositories under
/root/gitrepo/. You might want to be more restrictive than
that (say only ‘active’ repos), but this at least shows the power of the
generalization.
If you login to the server, you will find it doing some kind of work:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
As you can see, the total time to do a “Hello World” is under a second. Very fast!
Inherent overhead of approach
The amount of overhead associated associated with this approach is less than a second. The fetch itself:
1 2 3 4 5 | |
is 87 milliseconds and the system overhead is 8 milliseconds on an m1.small (that isn’t doing anything else). With a busier server the ‘real’ time goes up a bit, but the system overhead is still tens of milliseconds at most.
Although fetching is useful on its own, we will initially always merge as well, so let us time that:
1 2 3 4 5 6 | |
Pulling requires a bit more effort to do a no-op merge but things are still in the tens of milliseconds of ‘effort’ and a clock time well under a second.
Push-Me-Pull-You

The previous section discussed having ‘Live IT’ servers that use the very-fast git pull to get updates that the server will react to. Updating central git repositories uses an atomic ‘push’ operation, so the obvious name for this pattern of pushing changes from one place (say ‘me’) to a hundred servers who are listening (let us call them ‘you’) is… ‘Push-Me-Pull-You’… which even has a handy mascot.
Some great things about the PushMePullYou were identified above:
- Extremely low overhead and very simple model
- All changes to a server are caused by one or more git repositories changing. Servers can even publish there status by showing the git revision they are on.
- Rolling back changes is simply reversing a commit
- The only centralized activity is the
git fetchwhich is very simple and fast. - So far the only constraint is the time is every minute, and that could be sub-minute but needing that is rare
- Delays are at most a minute, and again that could easily become less (but not sub-second)
- The behavior is actually the same as bootstrapping a server. A bootstrap is just the first minute of work.
A few additional ones are:
- You can ‘push’ from anywhere you want… so you can test a change on the target IT environment and then push from there if it works
- It is very easy to organize many different kinds of machines, kinds of deployments, etc. within a single repository
- It is very easy to detect whether a change happens at all, whether it is potentially relevant, and with a few easy patterns, whether it would have an impact that requires real action
The architectural model looks a bit like this
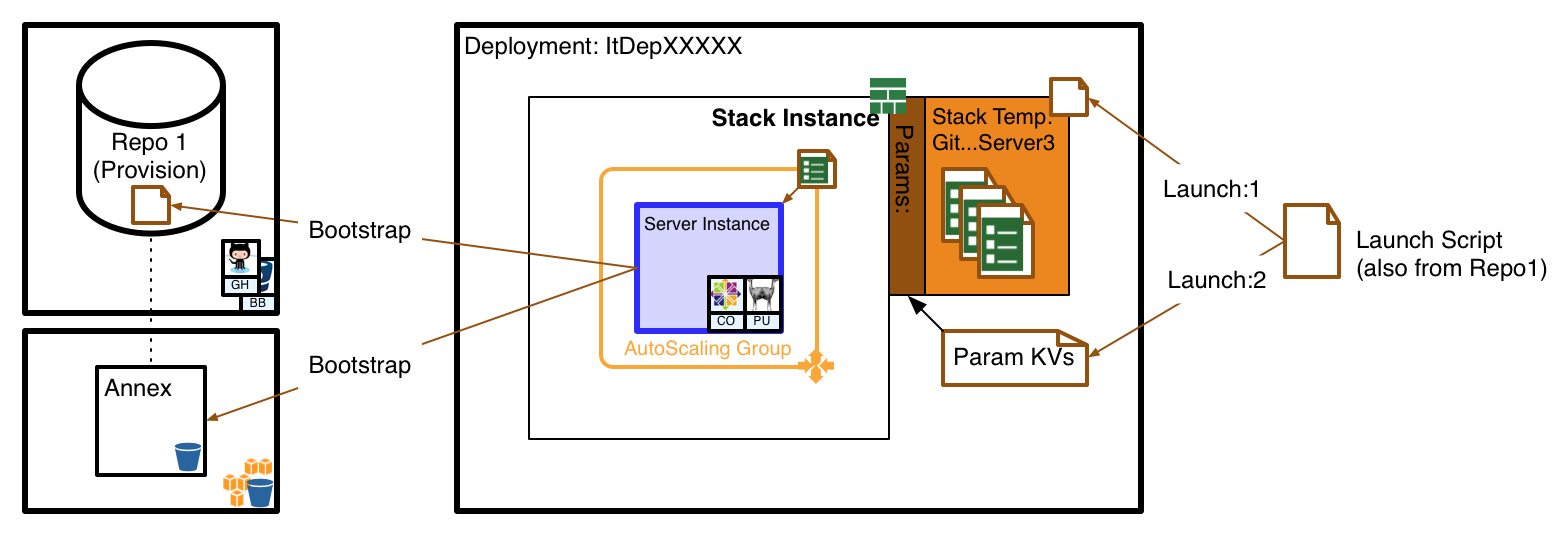
Going beyond naive
The Example-1 above had the naive ‘pull and do something no matter what’. We need to get a bit beyond that to have a truly useful approach.
Checking commit version
The simplest sanity check is to see whether we have a new commit. This can be done in a few ways, including:
- Do a ‘fetch’ and check whether the remote branch is different from the local branch
- After each action, store the commit version that was acted upon. On each pull compare the old to the new
- Have a local acted-upon branch separate from the main branch
The last one has a nice feature of showing ‘history-according-to-this-machine’ where the other two are purely ‘what is now’, but it is simpler to avoid having a per-machine branch and multiple versions (the differing merges depending on local history) occurring everywhere.
Fetch based
The simplest check is just to see if there are any differences between the ‘origin’ and the local branch. This
would look something like detectOriginFetchDiff.sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Where you can use this script with:
1 2 3 4 5 | |
This should be lightning fast. The only drawback is:
- If you don’t pull (merge) until after executing the script… you might not be able to easily change the code determining whether to executing the script
You can redo an action by forcing the local branch back a version. For example:
1
| |
Last-action based
An alternative to the fetch-based model is to record the last action performed by the local machine. This
deals with the drawback above: you already have the latest version of code no matter what. Also it starts
down the path of ‘mid-action’ protection (to avoid doing a change or sequence of changes on top of each
other). For example detectLastActionDiff.sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
And after completing any action you write the version into the lastaction version file:
1 2 3 4 5 6 | |
Avoiding mid-action collision
The main advantage of the Last-action approach is it starts down the path of
making sure you are not executing things twice. Alternatively, you could
have an flock associated with the calling script (say the cron_1m.sh),
but writing to a currentaction file is a bit more
OS independent, can document what version is being acted upon,
and supports multiple paths hitting the same file.
Ideally if anything is currently working, the automatic merge would stop,
so the test for currentaction should be very early. We should go
back to our initial worker example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
Note: If you want to have each repository have more control of it’s behavior you would need to move the
iftest and thepullinto the work file.
While the action is running you can either touch or copy
the current version into currentaction, and when
finished, delete or rename it. Since everything
is running so fast, you probably don’t need to do
an flock or even a second [[ -e ]] check. Acquiring
the lock is simply:
1 2 3 4 5 6 7 8 | |
Dealing with different types and collections of servers
All the above had a single type of machine watching any changes in the repository and doing the same thing. Although this does work if you have either very few servers or are happy with a plethora of repositories or branches, it would be good to have a way for many different types and collections of servers to share a single repository. We will deal with that in the next blog.
Summary
Git can help automate IT with a very fast and effective PushMePullYou model. Hundreds of servers can be continually polling one or more central Git servers to see if anything has changed and then act upon those changes. This provides history for any activity, a very fast response time, and almost no load when nothing has changed. Also, this approach enables bootstrapping and updating to use exactly the same paths.
In all, it provides a superior foundation for IT automation in spite of being so simple.
References
- Chef-Server Scalability
Credit
- Initial Llama for Push-Me-Pull-You Image credit: fiftyfootelvis / 123RF Stock Photo
Next
Our next problem will be Mass IT Automation