This is the fifth in a series of using git as part of interesting solutions to problems.
The first is here: Intro and the previous part of this topic is here: IT Automation
PushMePullYou or Leveraging git to enable mass-automated IT

The previous post dealt with the groundwork of having Git be a central part of IT automation. That showed the core idea but was a bit too simple to fully express the power of the approach. This post will be dealing with all the things that were left off, especially support for:
- Many different types of servers with both their own and shared ‘recipes’
- More complicated install/upgrade actions
- More sophisticated install behavior
- Multiple versions of ‘recipes’ and an ability to promote whole IT from development to production
- Getting information from other active repositories
To just jump-in and not be so incremental, I want to build the following deployment:
- A load-balancing layer that registers itself with the outside world and knows how to talk to the application layer
- An application layer that runs an application which may be updated at any time
- A database layer using a cluster of Riak servers
- A presence server that can record what servers are present (so other servers can leverage)
Each of these will be a different stack for easier management. There will also be a Control server which makes setting up the deployment easier (for example, it will make sure you have the latest AWS CLI).
The Control Server
To get everything up and running check out the repository:
1
| |
And then in the Amazon AWS console launch the control server with the file template at it/aws/cloudformation/GitEvery4ControlServer.template.
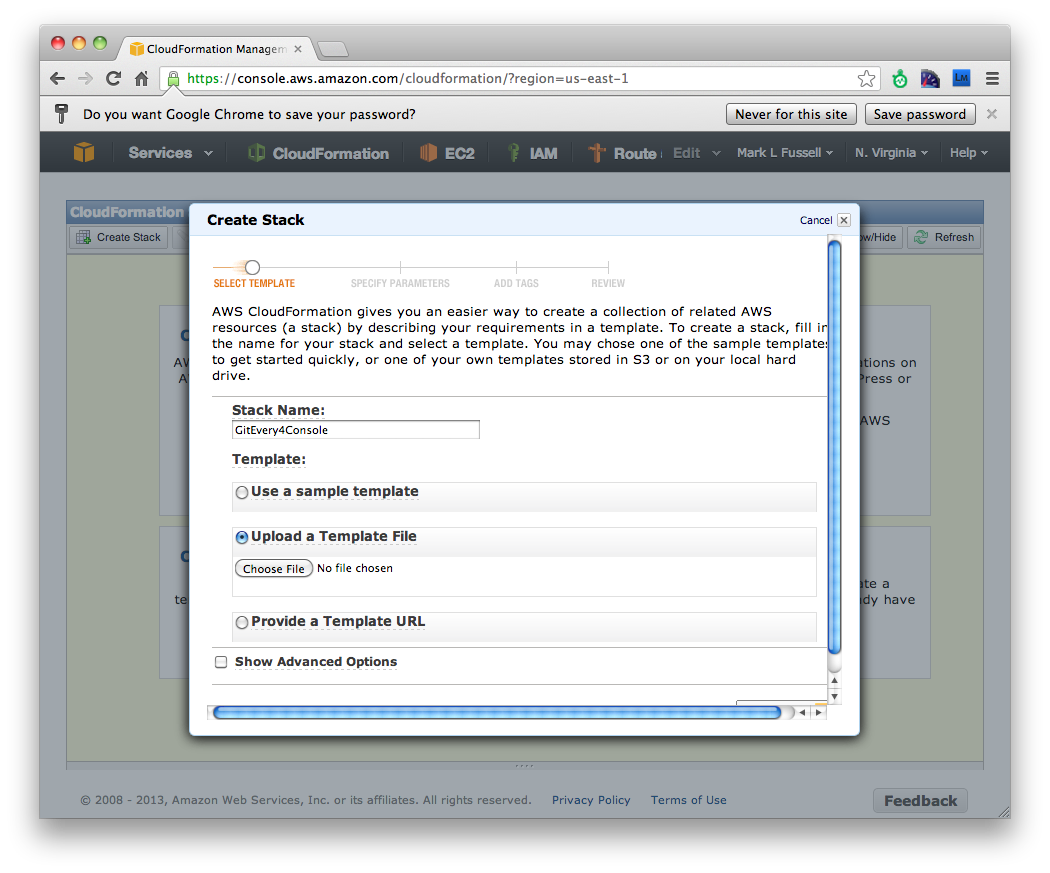
You can then SSH into the server and sudo su - to change to root. And cd gitrepo/giteveryrepo4 to get into the root of the repository.
Handling Different Types of Servers
A major difference from the previous example is there are now several types of servers, and they will have different:
- Firewall permissions
- Initial setup of software
- Ongoing configuration changes
There are also a number of similarities and ideally the CloudFormation files are as similar and simple as possible.
Firewall Permissions
One major change is to get rid of stack-generated security groups: these are difficult to manage since they have ever-changing and obscure names. I believe it is better for any real deployment to control the security groups independently of the Stacks. So now we have two kinds of security groups:
- One for the
deploymentas a whole - One for each
parta server node can be
The deployment and part are assigned as constants in the Stack template mappings:
1 2 3 4 5 6 7 | |
and then later referenced in the security group section:
1
| |
Before we create the stack, we create the appropriate groups. For example, the deployment group will enable SSH into
the nodes and any node within the deployment to talk to any other node:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Initial setup of software
Within the CloudFormation template, we use the same approach as last time: simply checkout a git repository and call into it. In Bash it would be:
1 2 3 4 5 6 7 8 | |
which is converted to JSON (string-quoted) within the template.
This entering on a common init.sh entrypoint makes the CloudFormation stacks simpler and more general. It is much
easier to update and push to the git repository than to update all the stacks that are using the repository.
The new part is now at the end of the common entrypoint: jumping into more specific initialization depending on the properties of the node:
1 2 3 | |
We so far have three variations:
- The
part - The
stacktype - Combining both of the above.
We can be as general or as specific as we want.
A stacktype is simply the name of the template (vs. the name of an instantiated stack which has to be unique).
The main advantage of stacktype is it allows easy separation of behavior by kind of stack and
also allows versioning if stacktype includes a version number.
A part is the singular role a node plays within a deployment. I use part instead of role to avoid
conflict with Chef where a node can have many roles. A node has exactly one part it plays in the deployment,
and each part can have any number of roles. A part should normally be fairly universal. In our case
the five parts are applbnode (The main application load balancer), appnode (The main app), riaknode (The
riak database node), presencenode (A server presence recording server), and controlnode (The main launching
control server, which isn’t really part of the running deployment).
With just the application and load-balancing parts/nodes running along with the controlnode, we have something like this:
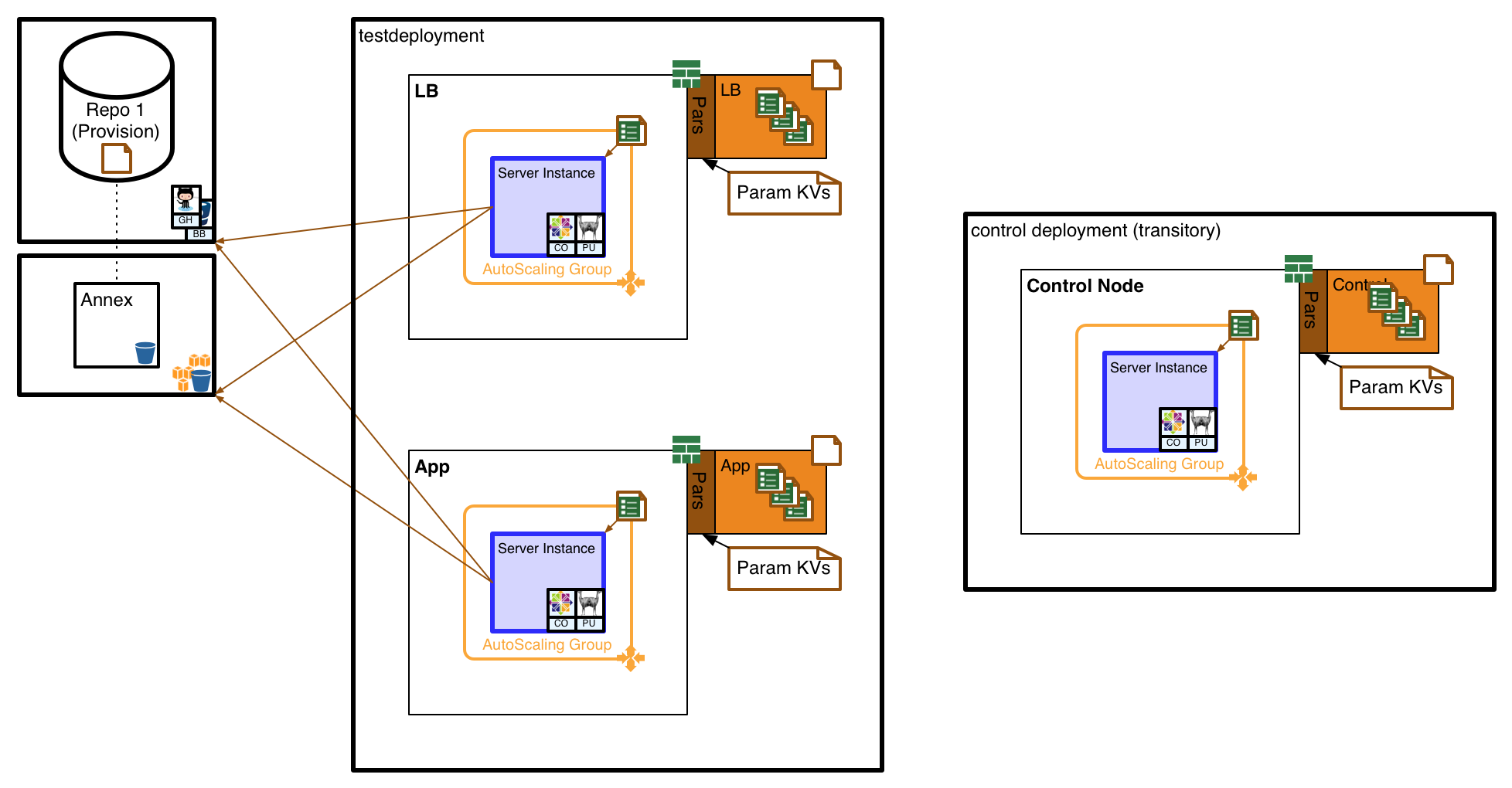
Each part has its own stack template and instance, which creates one or more nodes of that part type.
…More To Come…
References
- http://bitfieldconsulting.com/scaling-puppet-with-distributed-version-control
- http://blog.afistfulofservers.net/post/2012/12/21/promises-lies-and-dryrun-mode/
Next
Our next problem will be…