This is the eighth installment of describing a radically more productive development and delivery environment.
The first part is here: Intro. In the previous parts I described the big picture, Vagrant and EC2, node initialization, the one minute configuration HeartBeat, HipChat integration, presence, and EC2 integration.
Configuring Node Parts and even fuller Presence and visibility
So far our node was a generic ‘ControlNode’. A ControlNode is a node that is in your data center (to be near the other nodes), similar to your actual nodes, and configured to be able to do interesting tasks. It is not a critical part of anything, so you can fiddle with it and just throw it away. Say you want to start configuring a database node. You launch and login to a ControlNode and then try to install a database (for example Maria).
1 2 3 4 5 6 7 8 9 10 11 | |
Assuming you changed to root for the instance:
1
| |
This works! After confirming some things along the way…
OK, so now we want to have our database servers install MariaDB. We first need an ‘installMaria’ script with the above in it. Say
installMaria10.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
adding init
And unless you want every node to install Maria, you need to add an ‘init’ for the type of node we are dealing with. In our case, the StackType is ‘lad1’ (Load,App,Db,1) and the node type / part is ‘db1’.
So we get this hierarchy:
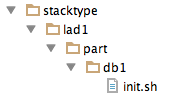
And the content of the ‘init.sh’ file is simply:
1 2 3 4 5 6 7 | |
CloudFormation
We have a new CloudFormation named ‘awscf4_Fed1Db1’ with the simple change of the nodepart being ‘db1’
1 2 3 4 5 6 7 8 9 | |
Demo or Die!
Since the previous presence description, the presence system has upped itself and now nodes check-in with more information than before. After launching two ‘app’ stack and one ‘db’ stack we get this:
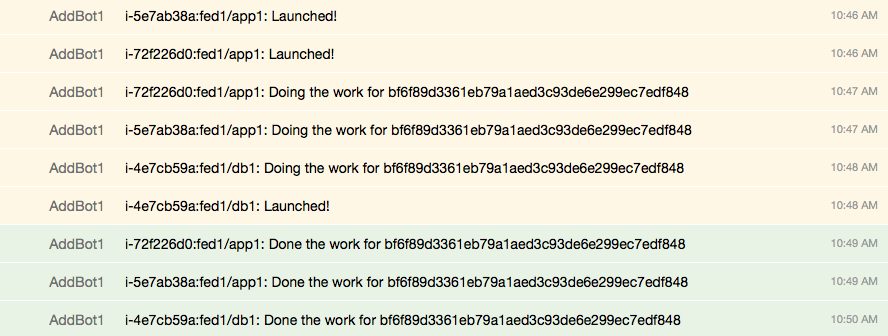
So clearly our nodes know who they are, what deployment they are in, what the ‘part’ in that deployment is, and how to “do work”. But are they actually what they say they are?
Being the ‘user’, fixing the ‘user’
If you use the installMaria script above, it will not work. Because I said: “This works! After confirming some things along the way…” During ‘boot’ there is no user to confirm anything. So the ‘yum’ part fails although the yum repository is there (the user is ‘root’ so it has permission). It ran the script but it didn’t work under ‘automation’. The three annoying issues in automation:
- The user could be different from the user you think it is (say ‘ec2’ vs. ‘root’)
- The user is not interactive
- The user did not “launch a login shell” and so some launch things that happen for you did not happen for them.
There are trivial and super-effective solutions to all of these, but until you get them right, you can bang your head quite a bit.
Who is the user? ‘root’
The user provisioning a machine should always be ‘root’. Yes, ‘root’ is dangerous. Because ‘root’ is powerful. And given (a) if you mess up you simply kill the machine, and (b) everything is from version-controlled source files… you can handle that power. So don’t add silly hoops to jump through. On a ControlNode, immediately ‘sudo bash’. And if for some reason the default user isn’t ‘root’ in a launch or cron script, ‘su root’ or ‘sudo bash’ to fix that.
Is the user interactive? ‘no’
We are doing production automation that is designed to scale into thousands of machines. No one is going to answer questions for thousands of machines. That is not ‘scalable’ or at all valuable. You should always know all the answers when a machine launches. So script any UI that really requires some value put in, or use the variant of a command that has default answers.
The true script for ‘installMaria’ has this line.
1
| |
The ‘yum -y’ should never ask any questions. But just in case it does, I give it a ‘y’ for every answer. If you are testing something and get a question, check if it has a flag like ‘-y’

Has the user launch as a login shel? ‘yes’
Since getting on a machine without ‘logging in’ is quite a bit more painful than ‘ssh’ into the machine, just make sure any ‘init’ and ‘work’ script has read the files a login shell would automatically read.
A simple ‘source /root/.bashrc’ fixes the problem immediately
1 2 3 4 5 6 | |
Node Work
Just like the ‘init’ hierarchy, the ‘db1’ nodes can have their own work items to do regularly by simply adding the ‘work.sh’ into the hierarchy:
