This is the seventh installment of describing a radically more productive development and delivery environment.
The first part is here: Intro. In the previous parts I described the big picture, Vagrant and EC2, node initialization, the one minute configuration HeartBeat, HipChat integration, and presence.
Fuller Presence and EC2 Integration
In the previous part, I went through a very simple but powerful model of ‘presence’ using simply GitHub repositories. The content of those presence statements was enough to figure out what nodes exist, but not much more about them. The second level of presence is to update the state of the node as it changes. For example, a node goes through a few bootstrap steps:
- presetup – The node before any updates are possible (no ability to change status)
- setup – The beginning of the ‘setup’ phase where the node is alive enough to change it’s status
- initdone – The time a node is done are initialization and can start doing ‘work’ as the ‘nodepart’ it is
A node getting to ‘setup’ is pretty important: before that it may be a zombie! And we don’t want zombie’s in our federation!
So far for the ADD we now have four resources within which track node states:
- On the node (say ‘/root/log’ or ‘/root/nodeinfo/state.txt)
- Within the presence system
- Within HipChat
- On EC2 itself
I recommend using all of them.
On node
On the node is very helpful in that it is isolated from any other failures. You can ‘tail’ the logs or ‘cat’ the state file. This tangibility helps understand things and debug if there is failure.
Within Presence
Within the presence system is the most powerful and flexible. It is easy to see history and all the activity of your nodegrid. And the nodegrid can use the presence system to figure out what nodes are present and in full ‘working’ mode.
HipChat
Within HipChat lets everyone see and talk about the changes. It can get noisy though, so you need to separate the ‘chatty’ state changes from the ‘critical’ ones. An example of ‘critical’ is when a machine realizes it is broken. It is running the cron job, but something is wrong and it can tell that the ‘work’ is not completable. I call this being ‘wedged’. If a machine is ‘wedged’, it should tell people and then we can work on improving its DNA so it can unwedge itself in the future. And then kill the machine.
EC2
By using EC2 tags you can leverage the EC2 dashboard. I view ‘tags’ as read-only because the ADD should not get attached (be dependent) on EC2, but it is helpful for visibility.
Examples
The following show two machines initializing through Presence, HipChat, and EC2. The only trigger for this was killing the existing two instances: the AutoScalingGroup automatically replaced them.
Launching viewed within EC2 Dashboard
Nicely the ‘add:’ prefix makes all the properties that are most important appear on the left. Some of the names of concepts are intentionally alphabetically ‘sorted’ so they appear in the correct column.

Click here: add7_ec2_cv1b to expand.
The ‘stacktype’ of ‘lad1’ in the capture is short for a stack of
- Load Balancer
- Application
- Database
Working viewed within HipChat
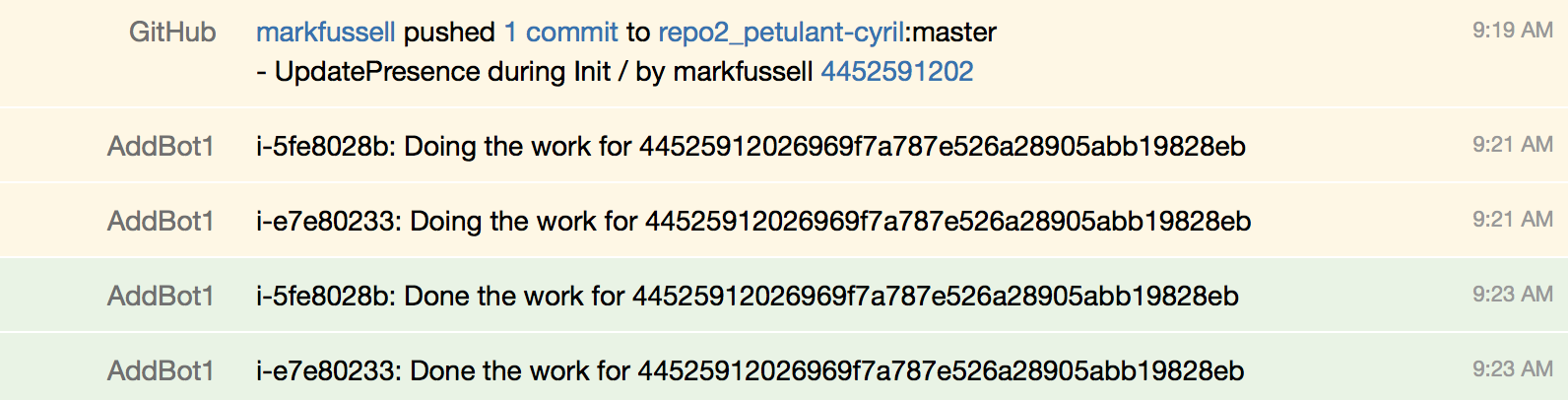
Working viewed within Presence / SourceTree