This is the second in a series of using git as part of interesting solutions to problems.
The first is here: Intro
Dealing with Binary Files
As mentioned in the first posting, git and similar DVCS have issues with binary files. Adding 100s of 10MB files, or 100s of versions of 10MB files will produce gigabytes worth of data that must be cloned by everyone using the repository. How do we avoid this?
There are a number of solutions in this space out there with differing characteristics, but the core approach is usually similar: “Don’t store it in git”. Instead we want to record enough information to retrieve the binary files from somewhere else.
Record Enough of the Binary File
What is enough information? How about 160 bits! Using SHA1 or any similar hash, we can identify the contents of any file. To add a bit of consistency and readability, we will make this hex-based, so we get 40 characters. And to make it a little clearer what hash was used and what this string is, we add ‘sha1_’ to the front and ‘.blob’ to the end. Now our 10MB file has become 50 to 52 bytes depending on human-entered white spaces. For example:
- sha1_8ac02ee34b94461fed19320d789f251e6a2a6796.blob
- SHA1-Hash = 8ac02ee34b94461fed19320d789f251e6a2a6796
- Google test: http://www.google.com/search?q=8ac02ee34b94461fed19320d789f251e6a2a6796
And we have confirmed that the hash is enough to identify that file’s content (and the file itself if it has a unique name).
Storing tens of thousands of 50Byte files is still under a few megabytes, so that part is good.
Put the content into the Cloud (or similar)
Where should we store the actual content? Pretty much anywhere we want if things are simple (only a few files at a time to store and retrieve, need only local access), but if we want to store and retrieve thousands of files from anywhere rapidly things get nastier. For example, there are projects that try to hide the process of file-contents being moved elsewhere using git smudge/clean filters. Unfortunately this make the process all of: sequential, heavy, and perpetual. We would have similar major issues if we moved the content via some other sequential approach that was not super-fast. And git is meant to be highly distributed, so our approach needs to work for all the ‘clones’ of a repository. And finally, we don’t want to break our bank over this.
The solution? Amazon S3 or similar. Amazon S3 is:
- Relatively inexpensive for what it does (about a dime a month for 1GB)
- Highly distributed
- Reasonably fast in network transfers
- Incredibly fast as you throw more workers at the network transfers
- Blazingly fast if you throw many workers from EC2 at it
So if we want to move files from our Git repository into S3, how do we do that? This isn’t really a git issue at all if we do it before ‘add’ and after ‘pull’. It becomes a simple filesystem-to-S3 issue and s3cmd http://s3tools.org/s3cmd is a very well trusted tool for this. Add in the parallel patch https://github.com/pcorliss/s3cmd-modification and you can have any numbers of workers running. We want to be a ‘git’ about everything, but we can solve this issue independently of git and combine the two. The only large remaining issues are the actual processes of:
- ‘deflating’: moving the content of a file somewhere and leaving a content-hash in its place.
- ‘inflating’: replacing a content-hash with the actual content
A highly annex-augmented version of s3cmd is here https://github.com/markfussell/s3annex and was done while working at Rumble where we needed to move gigabytes of high-quality art assets around as part of the build-deploy pipeline.
The architectural design looks a bit like this:
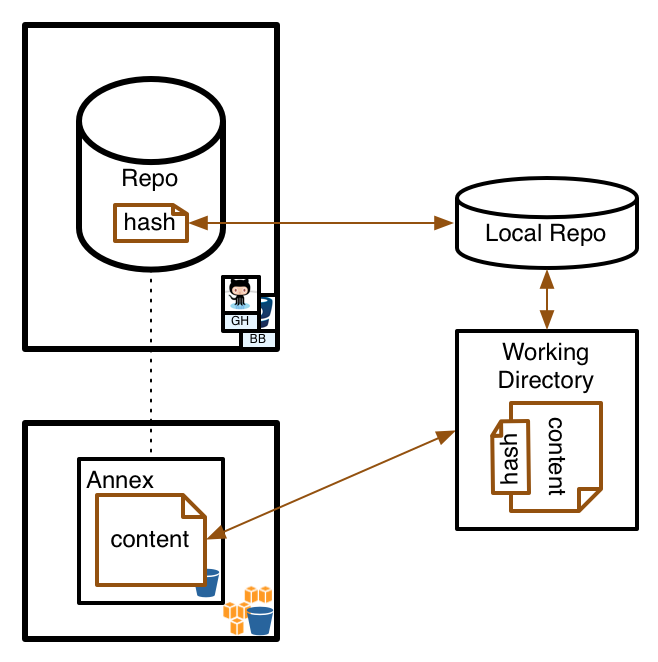
where the GH/BB repository in the upper left is just symbolizing pushing to some central repo. It isn’t required for the annex concept, but is standard Git behavior.
Working with S3 Annexed Git Repositories
The three things you need for an S3-Annexed repository are:
- A git repository
- An S3 bucket to put content into
- The augmented s3cmd from here https://github.com/markfussell/s3annex
A repository that is paired with an S3 bucket is located here:
You can clone that repository and get a working annexed-repository and some example content (without write permission). The repository is tiny but grants access to several megabytes worth of images.
Configuration
The configuration of the Annex is located in ‘s3info’:
- blob_includes.txt — The file extensions you want annexed
- s3annex_config.txt — The location of the annex
- s3cmd_config.txt — Some s3cmd configuration, but most importantly the access/secret
- s3worker_config.txt — The number of workers used for annexing
blob_includes
The blob_includes should be updated with any new file types you want annexed. To make things fast and simple, annexing is based on file extensions not size or other properties. It would be nice if this was more automatic, but being explicit was simple and very visible.
s3annex_config
This is simply the location of the annex. This can change over time as a quick way to do ‘garbage collection’ but normally it stays the same. Because of the content-based approach, you can share annexes across many repositories.
s3cmd_config
The s3cmd configuration including access credentials. If you don’t want access credentials in the repository itself, you could take out the s3cmd_config file and it should use your defaults (you may need to tweak a couple scripts).
s3worker_config
The number of s3workers to run at a time. More workers will make the S3 combined throughput faster: this should be 100 or more on an EC2 instance.
Working commands
All the commands expect to be run from the root of the git repository. The main working commands are:
- bin/deflatePaths.sh — Move the contents of files into the Annex and replace them with a hash stub/reference
- bin/inflatePaths.sh — Put the proper contents of the files into the filesystem based on their hash stub/reference
Because annexed repositories should always be fully deflated before committing, there is a command in the root of the directory to remind people of this:
- deflateAll.sh — Visible reminder and simple equivalent to ‘bin/deflatePaths.sh .’
These commands are all you need for annexing proper. To make it easier to see the Annex itself, there is also an ‘lsAnnex.sh’ script which is used below.
Annex (S3) Layout
The layout of the Annex within the S3 bucket is either:
- Flat in a single bucket plus path prefix
- Hierarchical based on some amount of leading hash digits
The completely flat version is the simpler and truer representation. The hierarchy simply allows multiple threads to get listings of the annex files in parallel, which matters for performance when you have thousands of files within the annex.
Annex listing
You can see the contents of the annex with:
1
| |
For the example repository, this gives:
1 2 3 4 | |
As you can see, in the annex are files that start with ‘sha1_’ and end in ‘.blob’ or ‘.blob__.xxx’ where ‘.xxx’ is a proper MIME extension. The reason for the MIME extension is just that it can be useful to see or directly retrieve the content with proper interpretation. The normal Annex behavior only uses the ‘.blob’ version.
The names of the files in the Annex match the ‘sha1’ hash of the contents of the file. So ‘sha1_55b15eb3ac72351249125a3de7a81aee2bda6a2a.blob__.jpg’ has a sha1 hash of ‘55b15eb3ac72351249125a3de7a81aee2bda6a2a’. It is impossible for files to collide unless they are exactly the same content, so a completely flat representation is correct and simple.
Example Walk-through
If you cloned the example repository:
you should have something less than a megabyte, but it represents more than 100MB of image files (30 images of 3MB each). But all the image files are stubbed out with just the content hash inside.
To see example details of these stubbed/annexed files, look inside any of the jpg files in image/album
1
| |
This returns the blob identifier:
1
| |
Inflating a file
To inflate a file, run ./bin/inflatePaths.sh with the specific file path:
1
| |
And you will get some feedback:
1 2 3 4 5 6 7 | |
Now you should have a normal file and can view a picture of Nob Hill.
Note that git status will now show a change. The approach here is not to hide or conflate annexing within git (e.g. being part of smudge),
but to create something that when combined with normal git makes git even more useful.
Deflating a file
Since we are in a git repository, we could simply do a reset to get the file back to it’s original content (it is already annexed) but it is much safer to always ‘deflate’ in case the contents changed vs. being the same as the original commit.
To deflate a single file you run ./bin/deflatePaths.shs with the specific file path:
1
| |
Because the contents are the same, you should see this:
1 2 3 4 5 6 | |
The original annexing of the file did upload two files, and looked like this:
1 2 3 4 | |
Inflating Many Files
The inflate and deflate scripts accept paths so you can inflate the whole album with:
1
| |
or even inflate the whole repository:
1
| |
With the default settings, this will launch 10 workers doing 10 files at a time in total. How long the whole 100MB download takes will almost likely depend on your maximum bandwidth, but if not, just change the number of workers to a larger number. S3 is very supportive of many requests by different workers.
EC2 Walkthrough
On EC2 the performance numbers are pretty amazing, so I created a simple CloudFormation so people can test it out. The CloudFormation is here:
and it can be run by going to AWS CloudFormation and just giving it one of your keypairs:
EC2 Performance
After the instance launches, SSH in, ‘sudo su -‘, and change to the repository:
- /root/gitrepo/giteveryrepo1
run inflatePaths with the standard 10 workers
1
| |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
So it took 10 seconds to download 100MB. That is 80Mb/s on an ‘m1.small’ which is a pretty nice number to work with. Changing to 100 workers doesn’t make much difference (about 9 seconds), so this is pretty much the saturation of ‘m1.small’ to S3 performance.
Larger instance types can perform even better. During a particularly grueling annexing, the performance numbers looked like this:
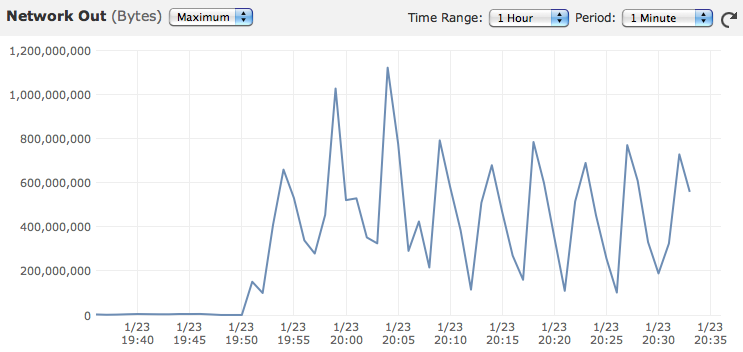
That is getting 200MB/s minimum and passing 1GB/s at peaks.
Summary – Annexing makes Git good at binary files
By using S3 as an Annex for binary files, we can make ‘git’ be exceptionally good at dealing with large amount of binary content. Git simply manages the history of 50-byte annex-stub text files, and git is very fast and efficient at doing that. The annex-enhanced s3cmd can run many workers to upload/deflate and download/inflate the binary files to and from S3. Especially on EC2 the performance numbers can be super-fast:
- Clone repository < 5 seconds
- Inflate 100MB of files < 10 seconds
By combining git with a powerful annex solution, working with lots of version-controlled information of any size has become all of: very simple, very fast, very distributable, and very inexpensive.
Alternatives
There are some alternative approaches out there, which I should mention. Some I tried and they didn’t perform well enough. Others didn’t match the needs we had at Rumble or my needs outside of Rumble. But they are interesting projects:
Next
Our next problem will be IT